

In this note, we want to draw on some history of how language models switched from very predictable inputs and outputs to arbitrarily complex ones as the models became Turing complete, capable of transforming any input to any output. Knowing this switch is important when designing a system whose goal is to detect and control the model's policy following behaviors; our goal in this brief note is to argue that designs that leverage input-outputs must expend much more energy than those that focus on the model itself.
Negroponte's Switch
In the 80s, Negroponte suggested a switch that has become known as the Negroponte Switch. Paraphrasing Wikipedia's entry:
The Negroponte Switch is an idea developed by Nicholas Negroponte in the 1980s, while at the Media Lab at MIT. He suggested that due to the accidents of engineering history we had ended up with static devices – such as televisions – receiving their content via signals travelling over the airways, while devices that could have been mobile and personal – such as telephones – were receiving their content over static cables.
It was his idea that a better use of available communication resources would result if the information, (such as phone calls) going through the cables was to go through the air, and that going through the air (such as TV programmes) would be delivered via cables. Negroponte called this process “trading places”.
AI's Switch
AI has also had a subtle switch that happened because of availability of resources. In the old days, pre GenAI, the inputs and outputs were simple. The complexity was the model internals. We had many different architectures but the inputs and outputs were standardized mainly because the dominant learning paradigm is supervised training where we use known input-output pairs to train a learning system. However, with the rise of deep learning the model internals also started on the standardization journey, with the inputs and outputs still remaining standardized also.
Convergence, at least architecturally, to a standardized model took full shape with the rise of transformers. Now vision, language and speech researchers spoke a common architectural language, accelerating the innovations; an important fact that is often neglected in the rise of AI today. But an interesting switch happened when Raffel and team in 2019 realized all inputs and outputs can be text, because autoregressive models had become so high capacity that the inputs and the outputs could be arbitrarily complex.
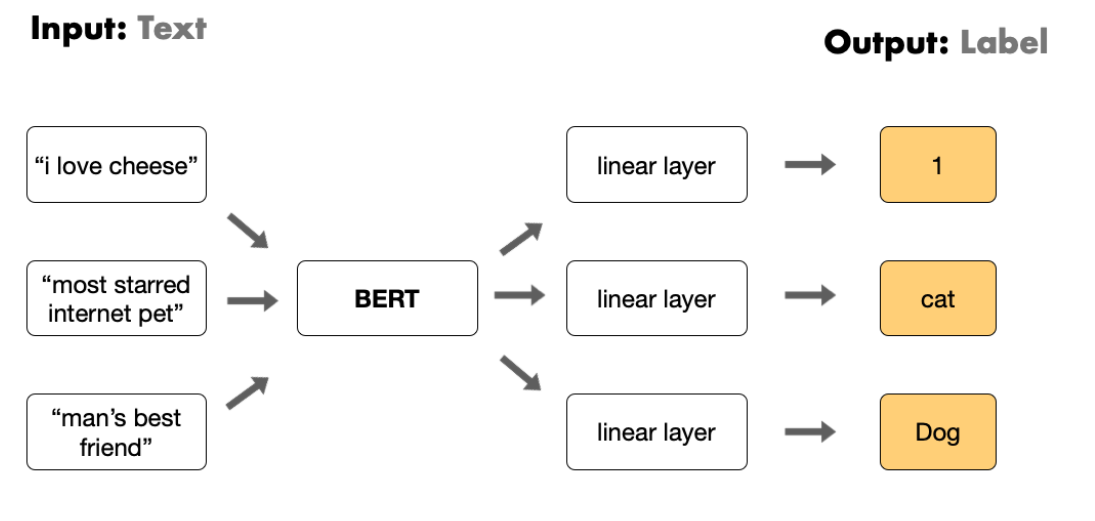
Specifically, to finetune transformers in the early days we had to fine tune a specific layer for each task (as shown in figure below). Inputs were text and outputs were task specific labels. The model had to comply with an output schema, not any arbitrary output.
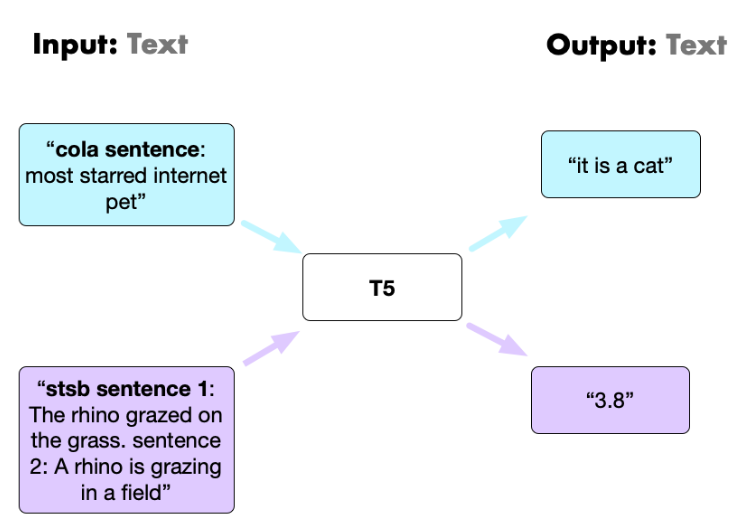
It was Raffel et al in 2019 that unified the task pipeline under one text-to-text architecture (Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer). Both inputs and outputs were now unified as text. However, under this regime the task class had to be prefixed to the input (see figure below).
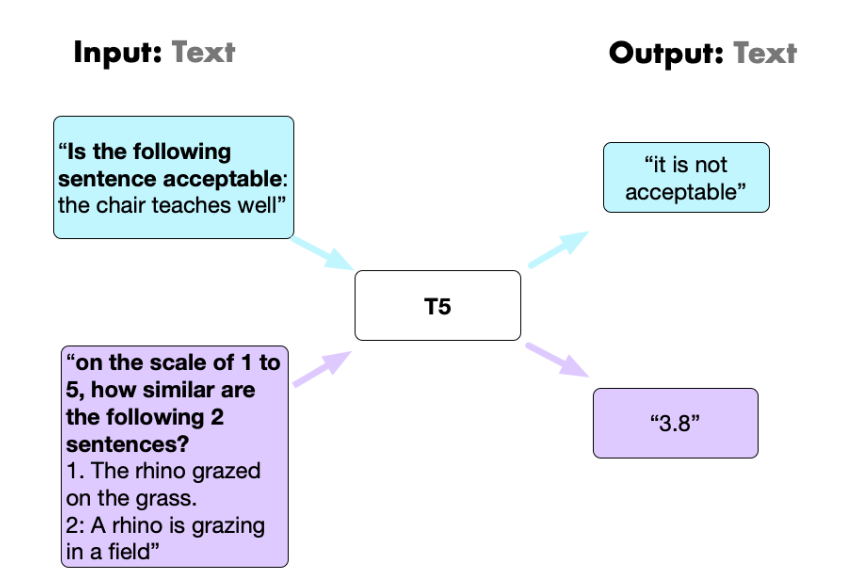
Full task unification occurred in 2021 by researchers such as Wei et.al to the world we are today, where the model does not need task signaling at input.
Consequences of the Switch
In summary, autoregressive models had become so high capacity and capabilities that we realized the inputs and the outputs could be arbitrarily complex. There are several odd consequences of this simple switch:
-
Firstly, as a researcher and developer the cognitive cost on me to understand a system was previously bounded and decayed over time because the inputs and the outputs were bounded. What was complex was the model internal but with enough time we learnt, and continue to learn, one architecture (the transformer). That appears not so anymore, at least to me. Now, when I read a piece of research or read an article or talk to someone working in the field I have to spend a lot of cognitive currency to understand what I am being told. And each interaction is kind of unique and my pattern matching primitive brain cant match. All because we now have a general purpose Turing machine which can accept arbitrary inputs and is backed by a Gigawatt data center that my 0.3 kwh biological brain cant compete with, relying on proxy selection signals like most liked, most followed, most educated, most XYZ signals to address this cognitively bounded rational that I am.
-
Secondly, and more relevant to our journey at Krnel, observing and controlling the behavior of the model with respect to some desired policy becomes infinitely costly because inputs and outputs are arbitrarily complex. Observing inputs and outputs leads to the curse of dimensionality and noisy estimators (as we've quantified in our previous blog).
A Path Forward
What these observations mean is that if we want to understand the artifacts we are building and to make sure they adhere to some policy then ironically one option is to flip the switch back to a state where model inputs and outputs are more standardized and can be checked -- give up generality for predictability and guarantees. Service Description Languages and schemas are some instances of this approach. But that genie is never going to be put back into the bottle. So the only viable option is what we at Krnel believe is the only agenda - arbitrary input-outputs but understanding and controlling the internal representations of the models.