

I attended Hyung Won Chung "Instruction finetuning and RLHF" lecture at NYU back in 2023. He made some very acute observations that has influenced how we think about design at Krnel. In that lecture he made a simple but sharp observation that over time we’ve been squeezing explicit inductive bias out of AI systems and letting models learn the parts we used to hand-engineer. In my diagram below, the blue boxes mark the pieces that migrated from “coded by us” to “discovered in training.” Any mistakes here are mine; the framing is by Hyung Won Chung [17]. I also highly recommend his MIT talk "Don't teach. Incentivize"
What is an inductive bias?
It’s the set of assumptions that lets a learner generalize beyond the data it sees. No bias, no generalization—this is textbook ML going back to Mitchell’s argument about the “need for biases” and the No-Free-Lunch results showing that, averaged over all problems, no algorithm outperforms chance without assumptions about structure [1, 2]. Typical examples: “nearby points have similar labels,” “images are translation-equivariant,” “shorter explanations are better.” You never get to literal zero; you only choose where the bias lives.
How the bias moved
Rules → Features → Representations → Objectives.
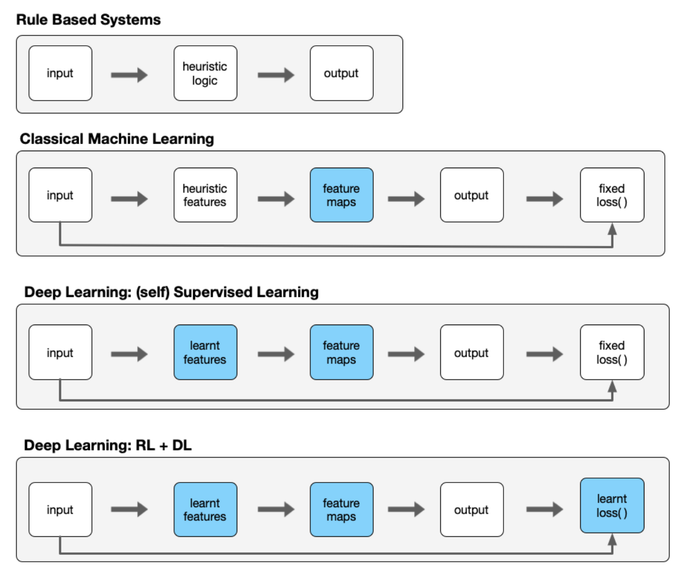
Early “expert systems” put the bias in rules: if temperature > X and WBC > Y then suspect infection. That works until the world deviates from your rule book. We then shifted to classical ML: fixed, convex objectives (hinge, logistic,...) and hand-crafted features. For example, in vision, SIFT was a bundle of human priors--local keypoints, scale/rotation invariance—baked into the pipeline; it worked because those invariances really do hold in many images [4]. In text, tf-idf and bag-of-words imposed the bias that word order is mostly ignorable and term frequency matters, which is often true enough to be useful [5]. The bias was explicit and upstream.
Then came Deep Learning rendering feature design as an endogenous process by the model. CNNs embed locality (unlike attentions of Transformers) and weight sharing, which is just another way of saying they assume translation equivariance. That’s an architectural bias, but it’s now inside the learner, not a preprocessor we maintain by hand [3]. Representation learning took off because letting the model learn features under a simple objective (cross-entropy) scales better than caretaking thousands of brittle heuristics [6]. Self-supervision turned the objective into a source of bias: with masked-token prediction (BERT) we assume that recovering blanked-out words is a proxy for capturing semantics [9]; with contrastive learning (SimCLR) we assume two heavy augmentations of the same photo should map nearby in representation space —- an explicit invariance assumption about crops, color jitter, etc. [8].
RL + DL learned the loss.
Instruction-tuned LLMs take biases a step further: collect human preference comparisons, fit a reward model to those judgments, then optimize the policy (often with PPO) against that learned reward [10, 11]. Now the effective loss is not a fixed formula (see this brilliant talk by Carlini on the challenges of alignment within the optimization framework [18]); it’s a model of what people want --- “be helpful but harmless,” “avoid disallowed content,” “be concise and polite.” That is inductive bias relocated to the objective itself. Two concrete examples: a reward model can push the system to refuse assistance with self-harm even when the next-token objective would happily autocomplete it; it can also nudge tone (“please,” “thank you”) because labelers liked those completions during preference collection [10].
Why keep doing this? Because compute beats cleverness in the long run. Sutton called this the “Bitter Lesson”: broad methods that exploit computation overtake knowledge-rich, hand-crafted approaches [12]. Scaling laws then made the returns predictable: loss falls smoothly with model/data/compute, so it’s rational to remove manual choke points and pour bias into learnable parts---representations and objectives—that improve with scale [13, 14].
Bias → 0 is a direction, not a destination
We still choose architectures, tokenizations, augmentations, reward data, and optimization constraints. Those are all biases. The question is which ones have better payoffs.
A concrete contrast: CNNs vs. ViT (Vision Transformers). CNNs keep image-friendly priors (locality, translation equivariance) and tend to win when labels are scarce. Vision Transformers relax those priors and rely on larger pretraining and heavier augmentation to recover accuracy; the bias is weaker in the architecture and stronger in the data and objective [3, 15]. As another example, geometric deep learning bakes in symmetry (groups, graphs, gauges). If your world is rotational or permutation-invariant—molecules, physical systems—encoding that prior can dominate brute-force scale, especially in data-limited regimes [16]. On the language side, masked-token pretraining assumes cloze-style prediction captures meaning [9]; RLHF assumes paired human comparisons are a good proxy for “quality” [10]. None of this is neutral and all are biases, just in different locations.
How to use this lens when building
Start by deciding where your bias should live. If you can state structure crisply (equivariance, conservation laws, monotonicity, etc.) encode it (architectures, constraints, augmentations). That buys sample efficiency and robustness [16]. If you can’t state it cleanly, push bias into objectives and feedback: self-supervised tasks for breadth [6,7,8,9], and learned rewards for alignment and policy shaping [10,11]. If you have abundant data/compute, prefer learned parts to hand-engineered ones (Sutton’s lesson + scaling laws) [12,13,14]. If you’re data-limited, keep the right priors (CNNs for small medical image sets; equivariant models for molecular geometry) [3,16]. Either way, you’re placing the blue boxes deliberately.
That’s the practical takeaway from Chung’s framing: treat “bias” as a resource you allocate, not a superstition you avoid. The modern stack keeps moving bias from brittle code paths into trainable components that improve with scale. Use that gradient when you choose what to hand-design and what to let the model discover.
In future posts we will use this framework to explicitly share why we designed Krnel products the way we did.
References
[1] T. M. Mitchell. “The Need for Biases in Learning Generalizations.” 1980.
[2] D. H. Wolpert, W. G. Macready. “No Free Lunch Theorems for Optimization.” IEEE Trans. Evol. Computation, 1997.
[3] Y. LeCun, L. Bottou, Y. Bengio, P. Haffner. “Gradient-Based Learning Applied to Document Recognition.” Proc. IEEE, 1998.
[4] D. G. Lowe. “Distinctive Image Features from Scale-Invariant Keypoints.” IJCV, 2004.
[5] C. D. Manning, P. Raghavan, H. Schütze. Introduction to Information Retrieval. Cambridge UP, 2008.
[6] Y. Bengio, A. Courville, P. Vincent. “Representation Learning: A Review and New Perspectives.” TPAMI, 2013.
[7] Y. LeCun. “A Path Towards Autonomous Machine Intelligence.” 2022 (self-supervised learning position).
[8] T. Chen, S. Kornblith, M. Norouzi, G. Hinton. “A Simple Framework for Contrastive Learning of Visual Representations (SimCLR).” ICML, 2020.
[9] J. Devlin, M.-W. Chang, K. Lee, K. Toutanova. “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.” 2018.
[10] L. Ouyang et al. “Training Language Models to Follow Instructions with Human Feedback.” NeurIPS, 2022.
[11] J. Schulman et al. “Proximal Policy Optimization Algorithms.” 2017.
[12] R. S. Sutton. “The Bitter Lesson.” 2019.
[13] J. Kaplan et al. “Scaling Laws for Neural Language Models.” 2020.
[14] J. Hestness et al. “Deep Learning Scaling is Predictable, Empirically.” arXiv, 2017.
[15] A. Dosovitskiy et al. “An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale.” 2020.
[16] M. M. Bronstein et al. “Geometric Deep Learning: Grids, Groups, Graphs, Geodesics, and Gauges.” 2021.
[17] Hyung Won Chung, "Instruction finetuning and RLHF lecture"
[18] N. Carlini: "Some Lessons from Adversarial Machine Learning" 2024