


Posts in this series:
The Enterprise Trust Gap
Frontier labs are building the on-ramps and highways for AI consumption, but enterprises need last-mile infrastructure to provision trust, reliability, and controls in the technology. Unfortunately, this gap is unlikely to be addressed anytime soon by frontier labs. They not only lack economic incentives, but more fundamentally, we lack a deep understanding of how these systems actually work. The latter skills problem is also unlikely to change anytime soon. By some estimates the world contains only about 150 people who know how to train frontier LLM models, and none of them truly understand how black-box models think at a level that's relevant to enterprise use cases. Frontier labs capture public imagination with research showing models exhibiting evil personas or sycophantic traits. But what traits do models hold for your organization's specific use cases - customer support, sales, marketing, research - all in your production environments?
The developers who train frontier models and the developers who deploy them seem to live in separate worlds, and there's an urgent need to support the latter group to build trust in AI for deeper adoption. The field of Mechanistic Interpretability (MI) is starting to create useful tools to this end, but the community is over-indexed on one dominant approach (Sparse Auto-Encoders) that isn't scalable, hasn't shown better ROI than simpler methods, and - critically - is only accessible to frontier AI researchers.
From our conversations, we're hearing that the biggest barrier to deploying AI is a lack of trust in the models, and the biggest barrier to developing confidence in LLMs is a lack of understanding how they work, how they fail, and how to customize them. The rest of the market has a limited vocabulary for AI trust: guardrails and prayer (a.k.a. prompt engineering). No wonder market trust in LLMs is still lacking.
Krnel-graph: The scikit-learn of LLMs
Today, we want to bring some of the field's other representation engineering tools out of the lab and into the hands of the broader developer community through krnel-graph, a practical MIOps framework that standardizes model interpretability tooling, like MLOps did before it.
In other words, we want to do to LLMs in 2026 what scikit-learn did to machine learning in 2014-2016. Scikit-learn democratized ML by providing consistent APIs (.fit(), .predict()), good defaults, and accessible abstractions that hid the complexity of optimization algorithms. You didn't need to understand Vapnik–Chervonenkis complexity to train a linear classifier. We're doing the same for model internals: krnel-graph gives you simple interfaces for extracting representations, training probes, and deploying controls. No Ph.D. required.
This announcement is the first of a three-post blog series. In our next post, we'll show you how to build better custom guardrails using krnel-graph. Our third post will talk about how to extend krnel-graph by writing your own operations.
Two Audiences, One Framework
We built krnel-graph to bring two groups together into the same framework:
Agent developers: You're hard at work building AI-enabled tools, agents, integrations, and chatbots.
-
You want to deploy models safely. You've tried an array of open and closed guardrails but they are opinionated, add latency and costs to your application, and not so accurate (specially against adversarial attacks) because they often treat your domain as out of distribution. You want to deploy your own on your use case, but don't know how. The total cost of building domain-specific controls seems too high.
-
You're interested in learning how to control what the model thinks, but you don't necessarily want to develop Ph.D.-level skill in machine learning.
With krnel-graph, you can use pre-built operations as simple building blocks without dropping into PyTorch or understanding the implementation details.
Data scientists and MI researchers: You've made handwritten notebooks and custom workflows with a mixture of Python libraries. Maybe you've had some success developing custom guardrails or models, but the opportunity cost to running ad-hoc experiments is high because:
- The majority of mechanistic interpretability research is still stuck in MLOps Level 0 - "Manual process"
- You're stuck in
results_final_v2_ACTUAL.parquethell, notebook hell, infrastructure hell, or hyperparameter/configuration hell - You need reproducibility and provenance, but this requirement is in tension with the ability to efficiently share and reuse previous computation results. Everyone runs their own separate experiments to generate their own separate result files.
- The same data and results need to be accessed in different contexts: TensorBoards, evaluations, OLAP queries, notebooks, presentations.
- With krnel-graph, you can extend the framework with custom operations while benefiting from automatic caching, provenance tracking, and team collaboration.
Both groups share a fundamental challenge: there's a significant gap between what cutting-edge AI research makes possible and what's practical to deploy in production.
What is krnel-graph?
At its heart, krnel-graph is a collection of high-level mechanistic interpretability operations alongside a principled, reproducible way of composing them together. We wrote this for our own use at Krnel because we needed a way of training probes that allows multiple developers to contribute results in a shared workspace without stepping on each other's toes or sending stale data.
We noticed that many MI experiments and pipelines involving probes tend to follow the same pattern:
- Dataset processing
- Representation extraction: Fetch an LLM's internal representation of each sample (e.g., extract how your model represents "dangerous content" across 32 layers, storing millions of activation vectors)
- Probe training: Train a simple and fast probe on these internal representations (e.g., a lightweight classifier that predicts safety violations from those vectors)
- Inference and evaluation on a test set
- Comparisons between the new probe and previous versions, other models, or third party guardrails
- Productionization: Bringing the probe into real-time conversations as a deployable signal
Downstream agent developers care most about steps 5-6, but they don't have a way to understand or influence steps 1-4. One barrier is that each AI researcher has their own handwritten pipelines and practices for these earlier steps, making it hard to distill the skill in a form that downstream developers can metabolize. To make matters worse, these steps are invoked in different contexts: some may run on laptops or notebooks, some on GPU machines or the cloud, some through local inference or an API provider.
Right now, krnel-graph addresses steps 1-4 through a small but growing vocabulary of reusable, composable, strongly-typed operations:
- Various primitives for data loading
- Operations for running LLMs in Huggingface Transformers, TransformerLens, or Ollama, extracting layerwise activations or token logit scores
- Operations for training, running, and evaluating binary classifiers or probes using these stored activations
Here's what the workflow looks like in practice:
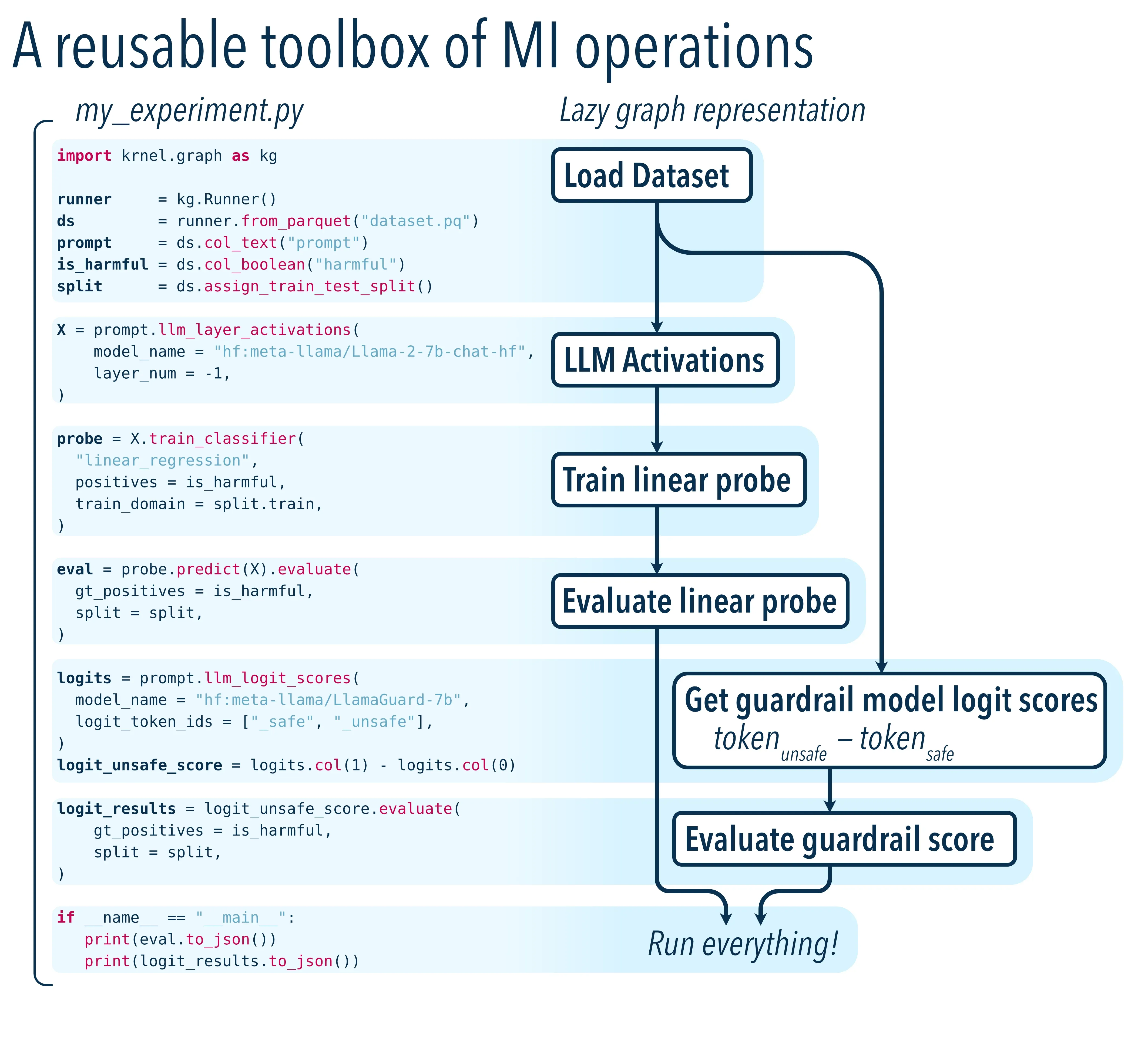
This is a simple MI pipeline that specifies a recipe of steps to run. We have a reference implementation, but it can be extended or replaced if your team has its own dataflow orchestration framework.
The key insight: If representation engineering collaboration could happen in-graph rather than in-PyTorch, these paradigms become accessible to more people. Work becomes more collaborative: results can be automatically shared between teams, data comes alongside its own provenance and reproducibility information, and pipelines are auditable and transparent.
After release, we want to implement more high-level operations focused on bringing probes into runtime inference frameworks (vLLM, hosted inference providers), agentic automation of probe training and evaluation, synthetic dataset generation, weak supervision, and beyond.
Why This Matters: Building Better Controls
Let's make this concrete. Current off-the-shelf controls like LlamaGuard require separate infrastructure, add latency to every request, can't be easily tuned to your specific domain or risk tolerance, and suffer from adversarial problems themselves. Most teams resort to taking existing controls and layering on prompt engineering, hoping for the best.
Probes trained on model activations offer a theoretically better approach: they look inside the model's internal representations rather than just at its outputs, often achieving better accuracy with lower false positive rates. But despite their promise, they've remained largely inaccessible to (and thus unused by) typical development teams.
Why haven't probes been adopted? There are three core barriers:
- Custom infrastructure hell: Every team builds their own one-off pipeline for extracting activations, training probes, and evaluating results
- It's not multiplayer: Every researcher who trains models has their own custom
results_final_v2.parquetpurgatory with no standardized way to share or reuse computation across experiments, or make them available to downstream teams - Productionization gap: Even when research succeeds, there's no standard API or format for deploying probes into runtime inference frameworks
So teams default to what's immediately available (existing guardrails plus prompt engineering) even when they know it's suboptimal.
This is exactly what krnel-graph is designed to solve. With a standardized MIOps framework for MI operations, you can:
- Collect activations once, then train multiple probes on them
- Iterate on your safety definitions without re-running expensive inference
- Extend your training regime to include more complex loops like adversarial training
- Share results across your team automatically with built-in provenance
- Deploy probes that are fast, interpretable, and customizable
In our next blog post, we'll walk through a detailed comparison showing how a krnel-graph-trained probe achieves 25× fewer false positives than LlamaGuard on a content moderation task. The one after will show engineers how to extend the graph to include new operations unique to your needs. The key insight: looking inside models beats treating them as black boxes... IF you have the right tools.
When developers can actually see what their models are doing internally, they can build controls that are both more effective and more trustworthy.
Beyond controls, our team at Krnel is already using representation engineering for:
- Hallucination detection: Probing for "uncertainty" representations to flag when models are confabulating
- Bias measurement: Extracting and quantifying demographic stereotypes in model activations
- Topic steering: Identifying domain-specific activation patterns to steer models toward or away from certain subjects (e.g., legal advice, medical claims)
- Adversarial model evaluation: Extract knowledge of systemic risk categories by undoing safety fine-tuning
- Model alignment: Aligning models upstream using representation methods
Where We're Going
At Krnel, we started krnel-graph to support our own internal research into policy neurons, weak supervision, and other high-level mechanistic interpretability pipelines. We're open-sourcing this now with a limited but functional vocabulary of MI tools to gather feedback from the broader community, make mechanistic interpretability more accessible, and establish a public data specification for our own products and services.
As the field matures, we want to add more tools (both free and paid) to this open-source toolbox. We'd like to see a broad variety of MI workloads expressible in krnel-graph, filling it with annotated examples, paper reimplementations, and tutorials that make representation engineering digestible to a wider audience.
Within a year, we want any developer to be able to say "show me when my model is uncertain," "steer it away from legal advice," or "detect when it's hallucinating" with 10 lines of code and no ML degree required. We want representation engineering to be as common as prompt engineering is today.
Even more ambitiously, we want to build agents on top of the graph that can automate the vast majority of work involved in going from high level requirements to deploying well calibrated, accurate and fast probes. Finally, we want to provide model and agent zoo where developers can download pretrained probes and/or agents for specific domain-risks tuples.
If we can lower the barrier to entry for understanding and controlling model internals, we can accelerate the trust and hence deeper deployment of AI systems across enterprises.
Get Started
Start now:
- Clone the quickstart tutorial and train your first probe
- Star us on GitHub to follow development
- Read the documentation for detailed guides
- Join our community (coming soon) to share what you're building
Get in touch: Interested in runtime integrations, commercial support, or want to discuss how representation engineering could help your use case? Reach out to us.
We're building the tools that make AI systems trustworthy and understandable. Join us.